
GPU Performance: Black-box and White-box Perspectives
Published:
最近调研了一些GPU性能模型相关的文章。这些模型关注通用场景下GPU kernel的运算性能,往往将GPU kernel看做一个黑盒子(而事实也确实如此),通过benchmark以及profiling tools给出的一些信息,来对kernel的运行时间进行预测。同时,在另一方面,为了能深入理解程序员对CUDA kernel的优化过程,我也阅读了NVIDIA提供的CUDA Best Practices Guide[1]。直接从程序员编写CUDA代码的角度来理解CUDA kernel可能存在的一些特性。现在将这两部分内容做一些整理和总结,从两个角度来对GPU kernel的性能进行分析。
Black-box: General GPU Performance Model
Roofline Model
Roofline 模型[2]其实并不是针对GPU提出的性能模型,而是可以被应用到各类处理器的一个通用的性能模型。
Roofline 模型使用了Operation Intensity这个指标,它表示operations per byte of DRAM traffic,简单地说,与Arithmetic Intensity类似,即每Byte执行的操作数。而Operation Intensity更加通用,不仅可以表示算术指令,也能表示非算术指令。值得注意的是,Operation Intensity所使用的DRAM traffic,是指Cache和Memory之间的数据量,而非处理器和Cache 之间的数据量。
有了Operation Intensity (Op/Byte),再乘上Memory Performance (Bytes/s),就能得到Floating-point Performance (Op/s, Flops/s)。Roofline模型就是将这三个关键指标统一到一张二维图中。如下图所示。
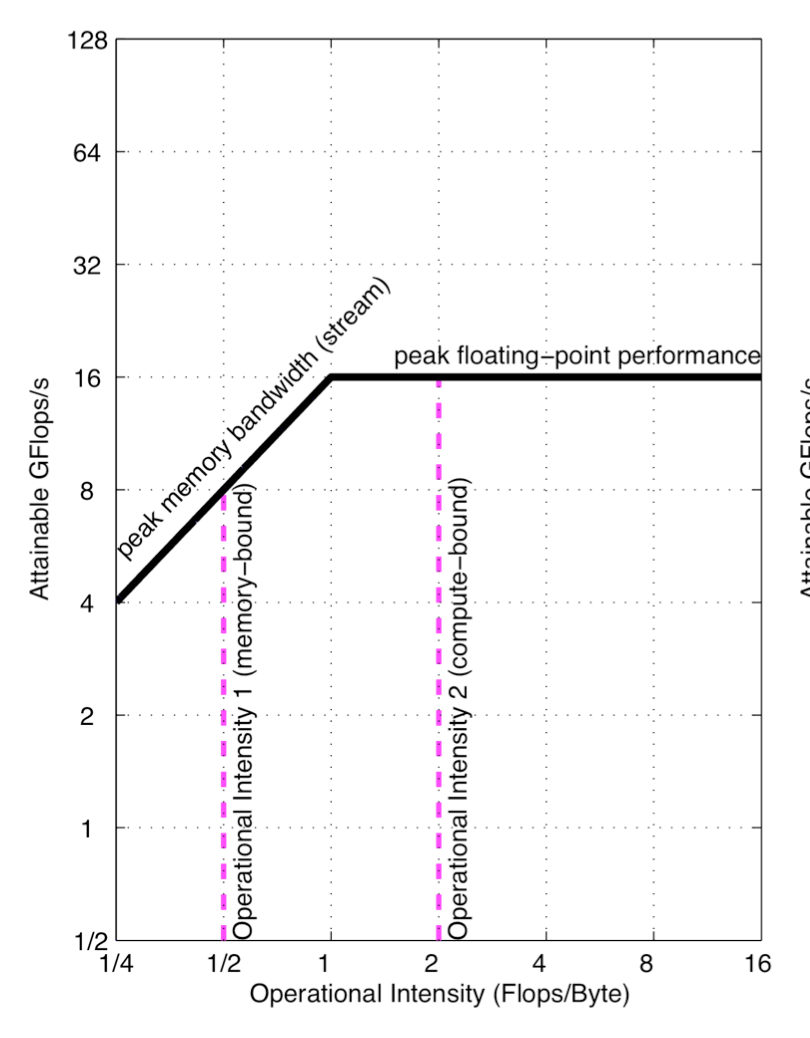
Roofline模型通过如下公式得到:
Attainable GFlops/sec = Min(Peak Floating Point Performance, Peak Memory Bandwidth x Operational Intensity)
其中,峰值浮点性能以及峰值访存性能可以通过硬件厂商给出的参数信息得到,但实际性能往往会比较低,因此可以通过一些工具(例如Berkeley开源的Empirical Roofline Tool)来测试当前硬件的实际Roofline模型。
Roofline模型给出的是程序可以达到的峰值性能。例如,图中左侧的红色虚线表示,在当前机器上,算术密度为1/2的程序,其能达到的峰值性能是8GFLOPs/s,由于没有达到当前机器的峰值浮点性能,所以这个程序是Memory-bound。但这不代表所有算术密度为1/2的程序都能达到8GFLOPs/s的浮点性能,程序很可能落在这条粉色虚线的任意一个位置,这跟程序自身的设计有关。当程序的算数密度较大时,可能落在右侧粉色虚线上,这时,程序就是Compute-bound。
程序之所以不能达到峰值性能,有很多原因。例如,memory coalescing(即把多次访存合并)在真实的程序上并不能很好地实现。例如,在GPU 的shared memory中,如果同一个warp的多个线程访问相同的bank,就会存在bank confllic,从而降低了访存的吞吐量。这些因素与程序具体的数据大小、数据分布方式、访存的步长、访存地址等有关,无法简单地用一个固定的指标来表示。
因此,Roofline模型其实对程序内部的实现一无所知,也不能用来对程序的性能做预测,只能用来粗略地对程序进行一个二分类:Memory-bound or Compute-bound?然后根据这个分类结果有针对性地去对程序进行优化。
例如,我们可以使用SIMD指令、Balance Floating-point Operation Mix来改善Compute-bound,增加浮点运算性能。改变访存的stride特性、Ensure Memory Affinity、使用软件预取等方式来改善Memory-bound,增加访存性能。当我们对程序进行了一些优化后,Roofline模型也会相应地发生改变,这篇文章称之为在Roofline模型中增加了“Ceiling”,来可视化这些优化效果,如下图所示:
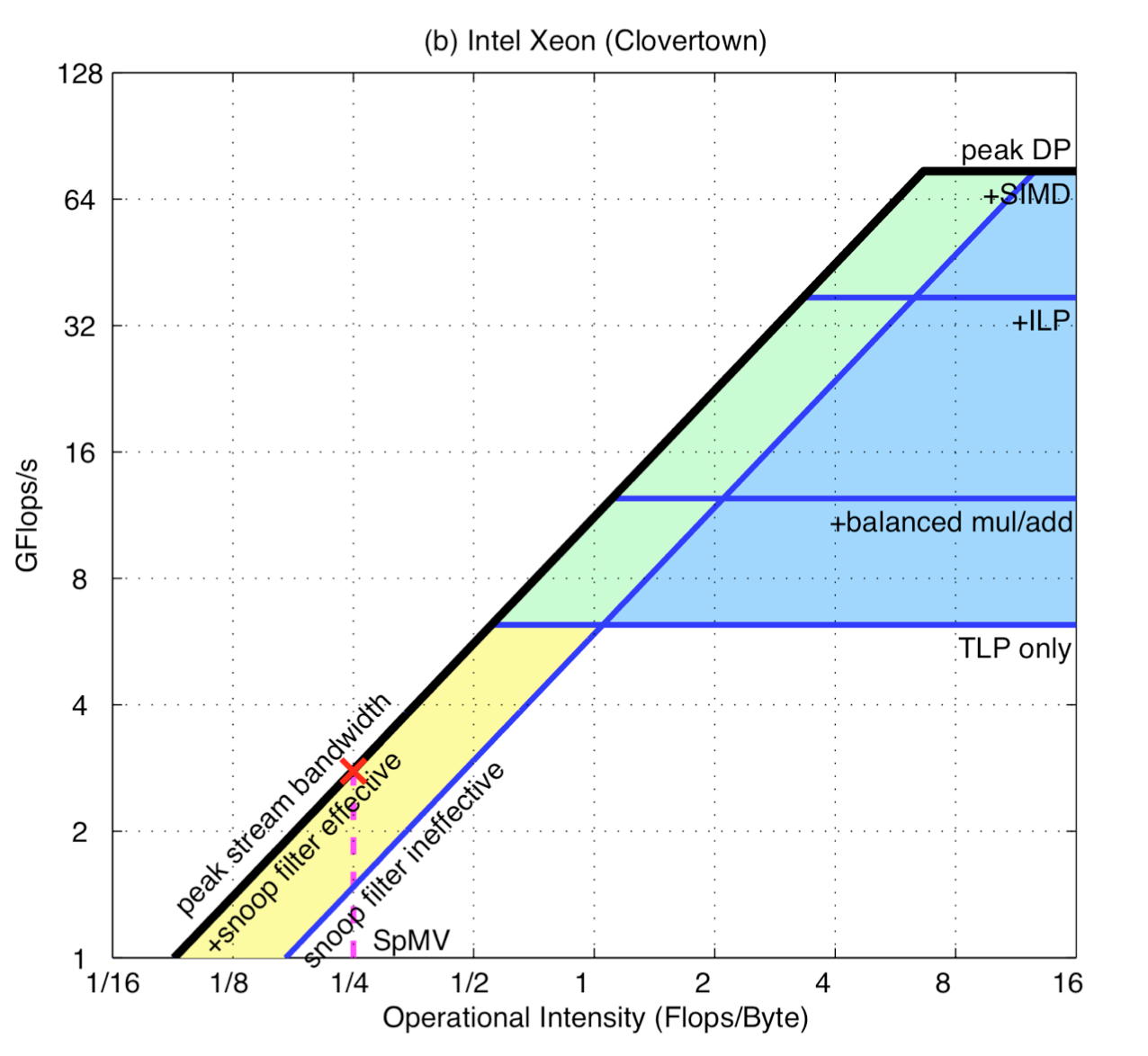
以上就是Roofline模型的介绍以及使用Roofline模型来指导程序优化的过程。对于同一台机器,其Roofline模型是固定不变的,只要我们通过一定的方式得到其Roofline模型,那么就能用这一个模型来指导不同问题的性能优化。
Cache-aware Roofline Model for GPU
上文提到的Roofline模型是针对各类处理器的通用模型,文章[3]则将Roofline模型应用于GPU,并且对GPU内部复杂的层级化存储进行了分析,通过Cache-aware Roofline Model来对GPU kernel的性能进行分析。
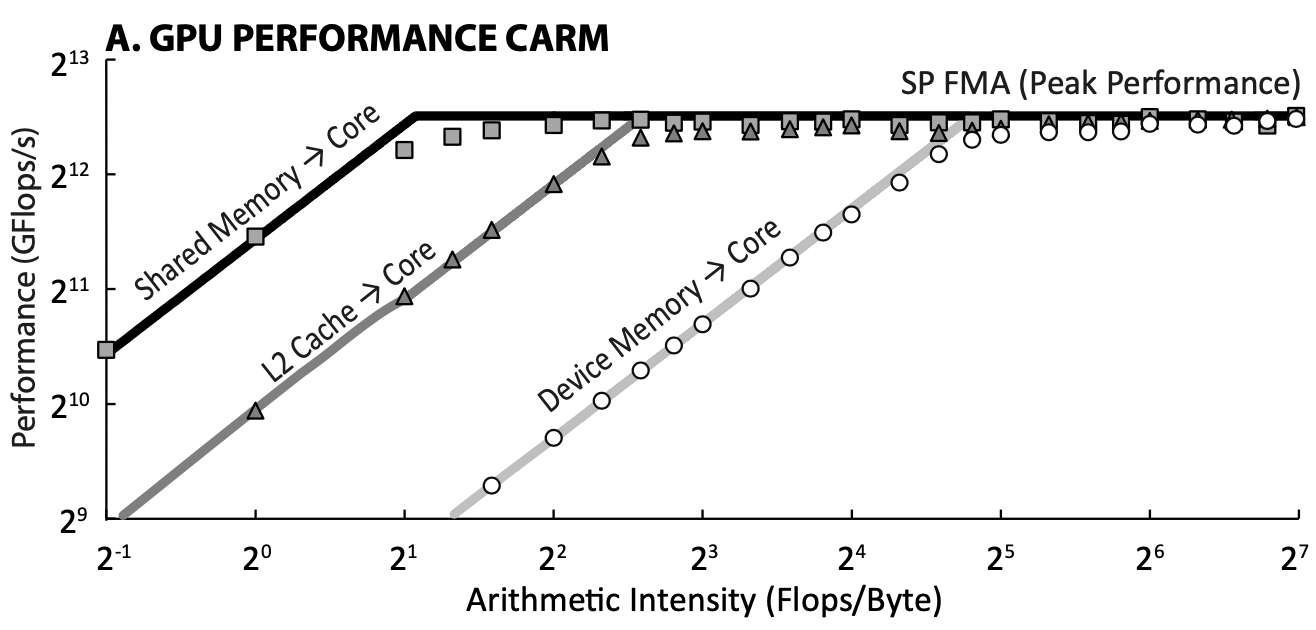
Quadrant-split Model
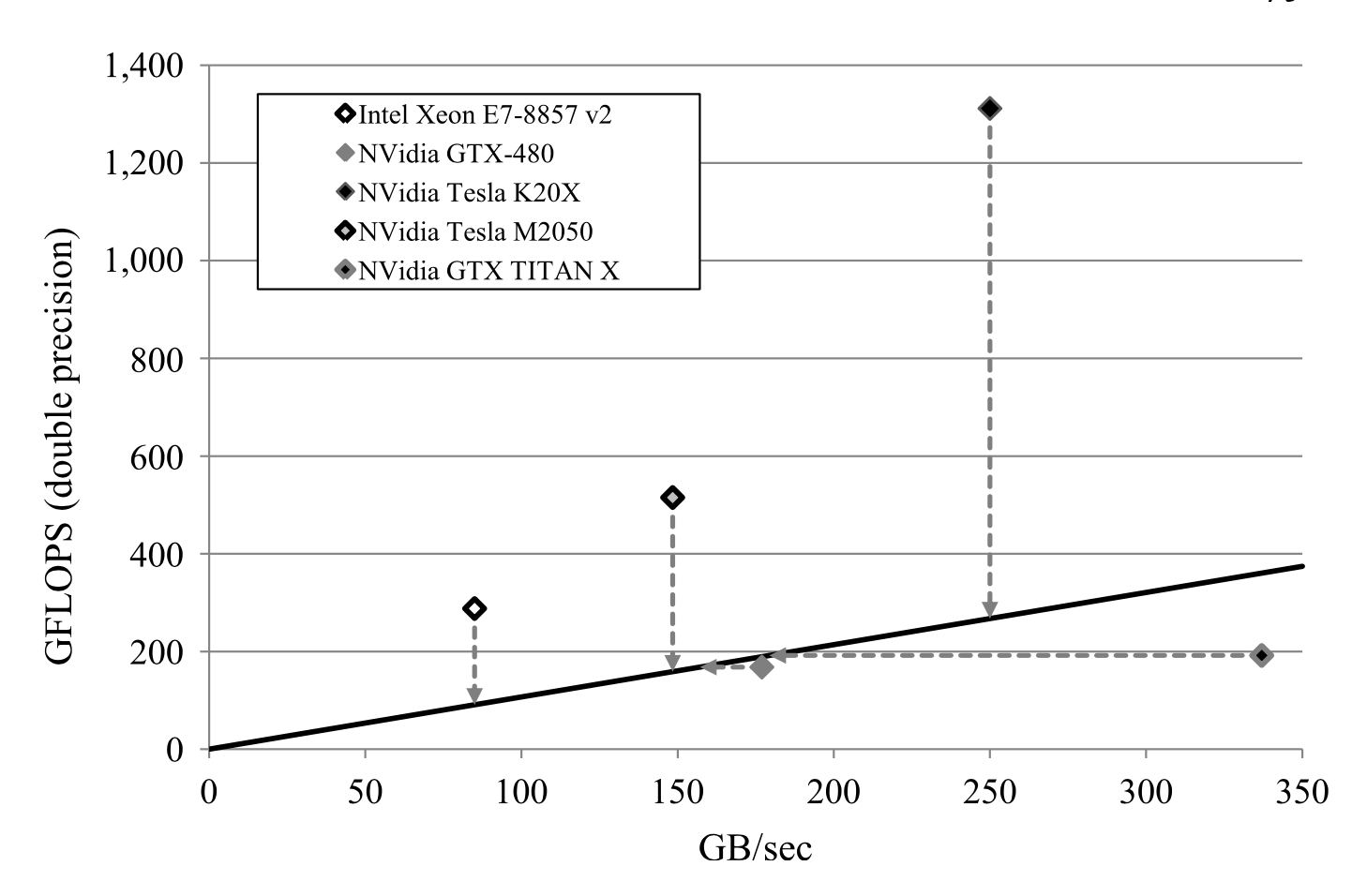
Roofline模型是device-centric,用于对同一个设备上不同问题进行分析,Quadrant-split 模型[4] 则是application-centric,用于对同一个问题运行于不同的设备上进行分析。
Quadrant-split 模型的横坐标是访存带宽,纵坐标是浮点性能,而直线斜率代表了问题的算术密度(即Roofline模型中的Operation Intensity)。如下图所示,每一个硬件设备都能在图中找到一个对应的位置。例如图中的TITAN X,虽然有比较大的访存带宽,但浮点性能有限,最终该程序的峰值浮点性能即为TITAN X的峰值浮点性能,表明该程序在TITAN X上是Compute-bound。
基于Roofline的时间预测模型
文章[4]基于Roofline模型的思想,提出了一套工具链来预测某个GPU kernel在target GPU上的运行时间。整个过程如下图所示:
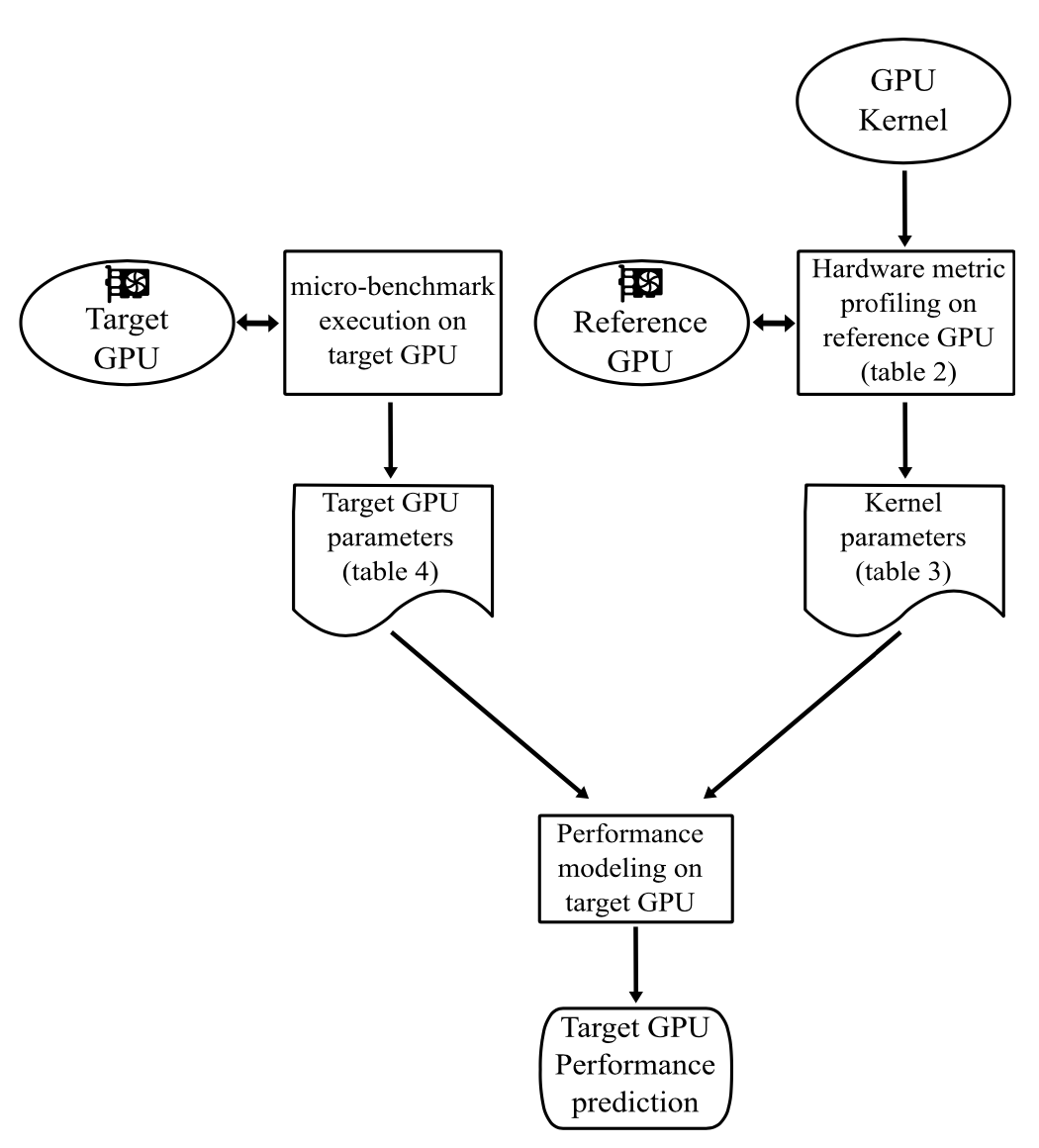
收集GPU kernel的一些指标,例如浮点运算次数、指令数、访存次数等。这些指标是与硬件无关的,所以在一个reference GPU上收集,也能被用于后续预测其他target GPU上的性能。
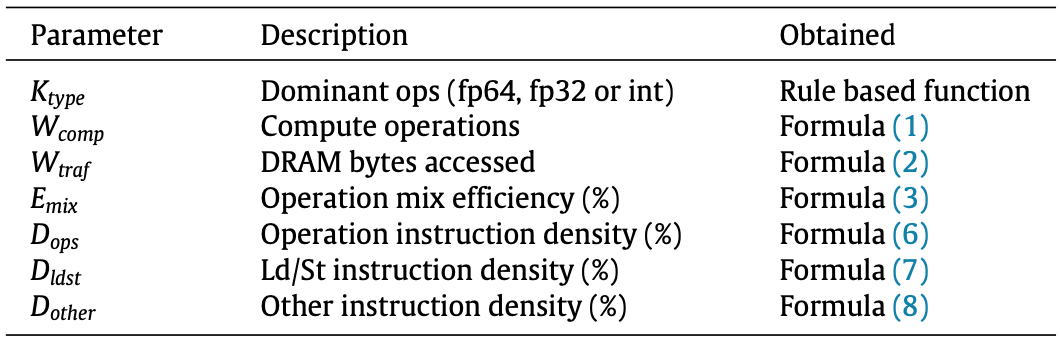
利用第1步收集的硬件指标,计算kernel parameters,如下表所示:
在target GPU上执行micro-benchmark,收集GPU的峰值性能(浮点、访存)。

用以上两张表格中的各类指标来建模GPU kernel的运行时间。
这篇文章建模kernel运行时间的主要思路是,考虑这个kernel里的各类指令,针对不同指令所占的比例、指令的operation intensity等因素,给出kernel的准确的Compute throughput的预测。(注意,预测的是compute throughput,即Roofline模型的纵轴。)
首先根据dominant Instruction type给出初始Compute throughput:$T_{op}$。然后定义一个指令权重$W_{op}=\frac{T_{SP}}{T_{op}}$。以及指令的密度$D_{op} = \frac{I_{op}}{T_{total}}\times 100\%$。结合指令密度和权重,得到指令的相对开销$C_{op} = D_{op}\times W_{op}$。类似的,我们可以得到访存指令以及其他指令的相对开销:$C_{ldst}$, $C_{other}$。
根据以上得到的这些中间参数,可以定义一个指令efficiency:$E_{inst}=\frac{C_{op}}{C_{op}+ C_{ldst}+C_{other}}\times 100\%$
另外,并不是所有同类型的指令都执行相同数量的操作。GPU中常用的一类指令是Multiply–Add instruction,一条指令执行两次操作,一次乘法,一次加法。如果一个程序中全部是Multiply–Add instruction,那么它的compute throughput就会很高。我们用Operation mix efficiency来表示程序与峰值性能的相对比例:$E_{mix}=\frac{M_{fp32}+M_{fma32}}{2\times M_{fp32}}\times 100\%$.
结合以上得到的两个Efficiency,我们可以对原始的Compute throughput作以下调整:
$T'_{op}=E_{mix}\times E_{inst} \times T_{op}$
根据对kernel做profiling得到的数据可以求出kernel的Operation Intensity:$O_{krn}=W_{comp}/W_{trans}$,通过我们的建模调整后的device Operation Intensity为:
$O_{dev} = T'_{op}/B_{mem}$
那么最终给出的Compute throughput预测值为:
$T'_{op} (Compute-bound)$
$O_{krn}\times B_{mem} (Memory-bound)$
分析:完全基于metric来对GPU kernel的时间做预测,感觉意义不是很大。既然能够profiling这么多的硬件指标,为何不直接profiling目标程序的性能?(这也是我们的工作被质问的一点)。而且,在在这一整套建模的流程中,需要估计的量太多,每个估计量都存在一定的误差,最后将这些误差叠加,会导致误差被放大。我认为这也是这个工作的预测准确率不是很高的原因(在30个GPU kernel,6种GPU上的平均绝对误差27.66%,最差的情况下有超过100%的误差。如果使用均方根误差率,效果应该更差。)
基于Abstract Instruction Queue Model的时间预测模型
文章[5] 提出了一个Abstract Instruction Queue Model,将GPU kernel内部的指令执行过程抽象为4个步骤:从Global Memory中读数据、从Shared Memory中读数据、计算、向Global Memory中写数据。根据一个kernel中不同类型指令的比例,可以将GPU kernel分为两大类:Compute-bound和Memory-bound。
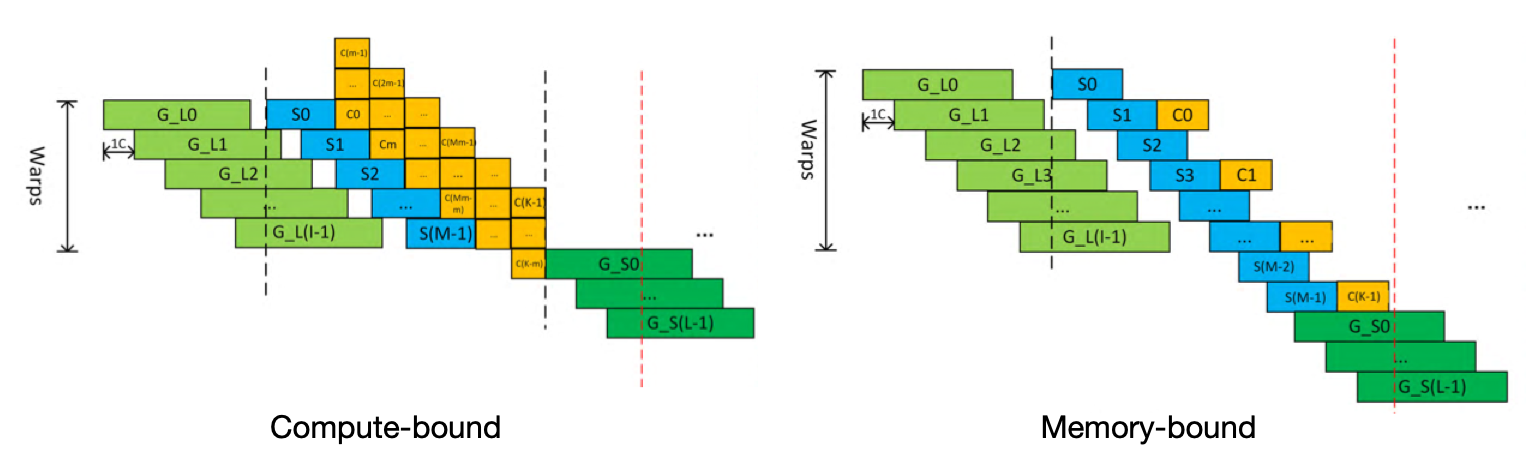
文章是提前通过GPU给出的指标,确定每类指令所需的GPU cycle数,然后建模一个GPU kernel所需的总cycle数,再乘以GPU一个cycle所需的时间(频率的倒数),得到一个kernel的运行时间。
Memory-bound 时间建模
由于计算指令完全被访存指令Overlap,因此只需要建模访存指令的时间开销。
迭代次数: $N_{iter} = \lceil \frac{block_{num}}{sm_{num}}\rceil$ (这里的block是kernel任务划分后的thread block。所有的block不能一次执行完,因为硬件流处理器有限,只能多次迭代执行。而GPU的并行特性使得总时间与block数量无关,而跟迭代次数有关。从这个公式能体现出GPU的“跳变现象”,但此处的是Wave Quantization,我们论文中关注的是Tile Quantization,具体区别请见Performance Model of Convolution on GPU)
一次block iteration中的Global Load指令数:$I=\frac{GL_{dispatch}}{N_{iter}}$ ($GL_{dispatch}$:Kernel总的Global Load数) 一次block iteration中的Shared Load指令数:$M=\frac{S_{dispatch}}{N_{iter}}$ ($S_{dispatch}$:Kernel总的Shared Load数) 一次block iteration中的Global Store指令数:$L=\frac{GS_{dispatch}}{N_{iter}}$ ($GS_{dispatch}$:Kernel总的Global Store数) 一个block(或者说一次block iteration)总的clock cycle数:$C_b = I + M + L$ 一个GPU kernel总的clock cycle数:$C_k=C_b\times N_{iter} + L_{GS}$ ($L_{GS}$:Global Store Latency)
Compute-bound时间建模
对于Compute-bound类型的kernel,一个最大的难点就是如何确定计算指令和访存指令Overlap的程度。在这篇文章中,作者提出用GPU中的计算单元和访存单元的数量来表示overlap的程度: $m = \frac{SP_{num}}{LDST{num}}$ 其他指标的建模与Memory-bound类似。
一次block iteration中的计算指令数:$K=\frac{CP_{dispatch}}{N_{iter}}$($CP_{dispatch}$:Kernel总的计算指令数) 一个block(或者说一次block iteration)总的clock cycle数:$C_b = I + 1 + L_S +\lceil \frac{K}{m} \rceil + L$ 一个GPU kernel总的clock cycle数:$C_k=C_b\times N_{iter} + L_{GS}$ ($L_{GS}$:Global Store Latency)
分析:这篇文章提出的Abstract Instruction Queue Model将GPU内部的执行过程可视化了,比metric-driven的模型要直观许多,但是这样的高度抽象过于简略。对于Compute-bound类型的kernel,如何确定overlap的程度不能直接用SM和Load/Store unit的比例来近似,真实情况会复杂很多。并且,这篇文章的方法需要我们对kernel本身有一定程度的了解,例如,知道它是Memory-bound还是Compute-bound,知道这个kernel会被划分为多少个block,这些信息不一定能得到(例如cuDNN)。
White-box: CUDA Optimization
访存对于GPU kernel的性能影响最大。 不论是从Black-box视角去建模程序的性能,还是从White-box的视角去优化程序的性能,访存往往都是瓶颈。而GPU内部的层次化存储结构以及Cache的使用,使得准确建模访存开销十分困难。
尽量减少Host Memory与Device Memory之间的拷贝。GPU与Device Memory的带宽(898 GB/s on the NVIDIA Tesla V100, for example)远大于Host Memory和Device Memory之间的带宽(16 GB/s on the PCIe x16 Gen3)。并且每次传输会引入额外的开销,因此最好将多次小的传输batch成一次大的传输,即使这会引入因为访存区域不连续带来的packing和un-packing开销。
Coalesced Access to Global Memory
一个warp中所有线程并发访问Global Memory时,这些请求会被合并成一些transactions,每个transaction访问Global Memory中的32 bytes数据。例如,一个warp中的32个线程,如果每个线程访问global memory中相邻的一个4-byte 数据(float),那么这32个线程的request会被合并成4个transactions,在图中用红色区域表示:
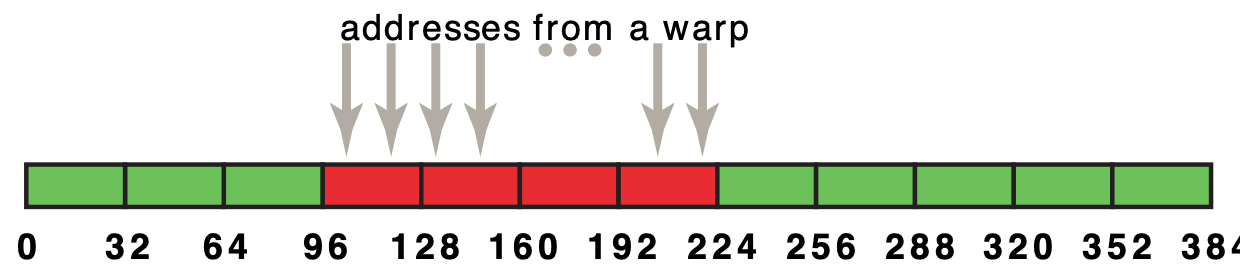
如果这32个线程的数据并不是刚好对齐的,那么将会产生5次transactions:
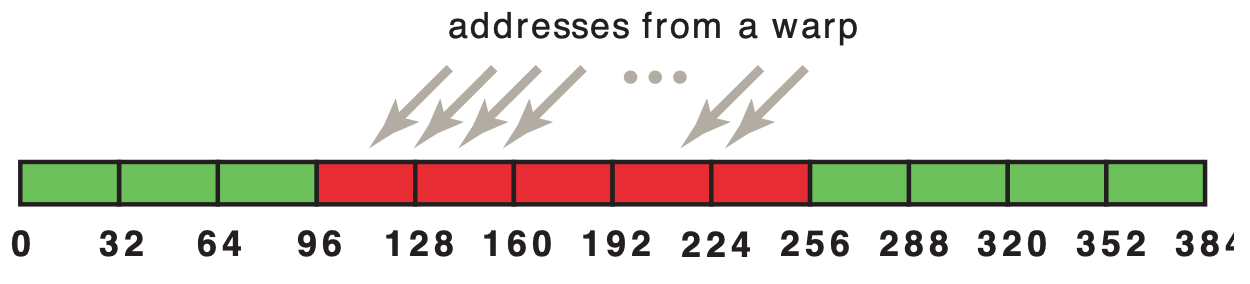
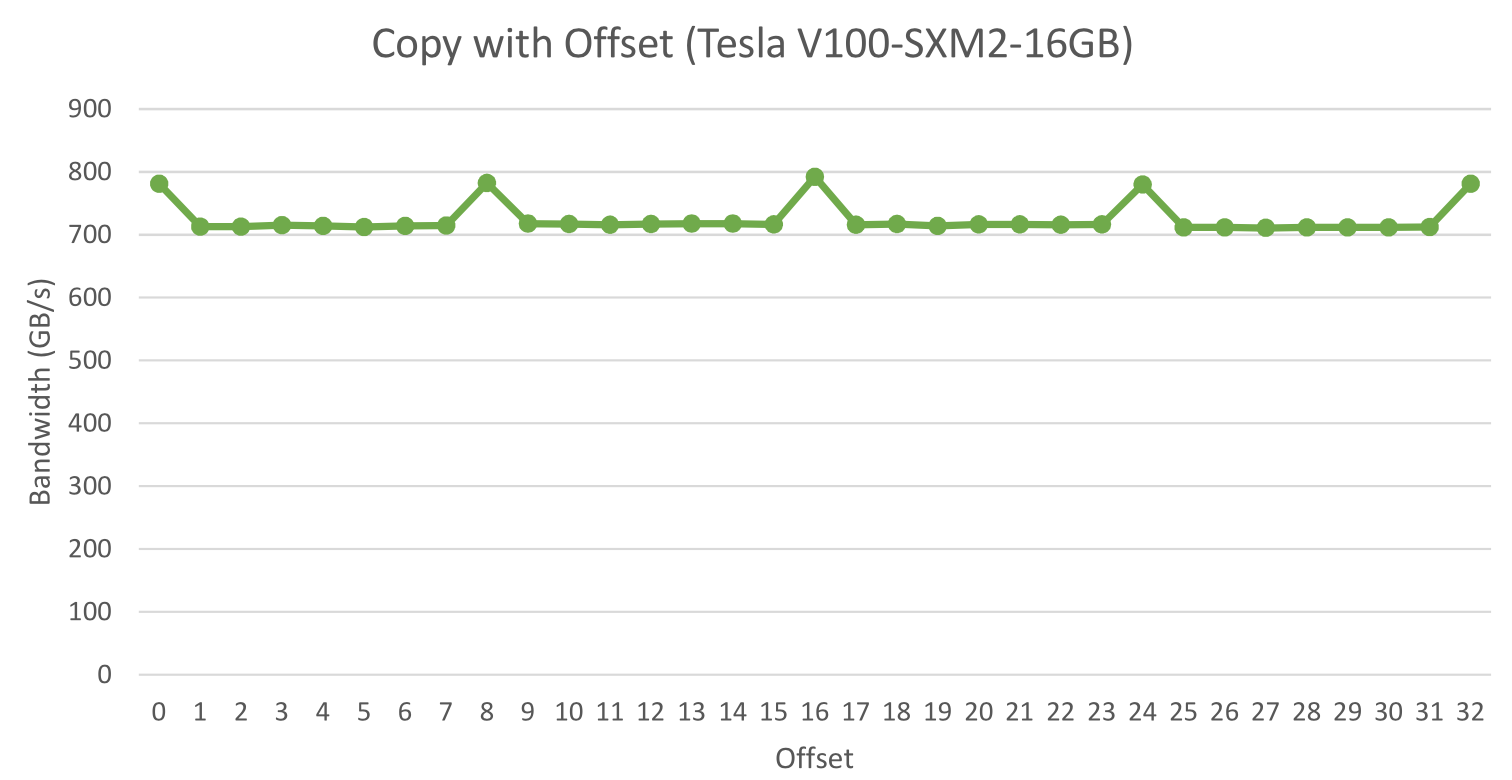
图中展示了一个简单的copy kernel,当数据不对齐时,达到的峰值带宽只有对齐时的90%。
Strided Access to Global Memory
当一个warp中的每个线程按照一定的步长访问global memory,也会造成有效带宽的降低,因为每次transaction只能访问连续的数据,那么步长越大,浪费的带宽就越多,有效带宽就越低。如图所示:
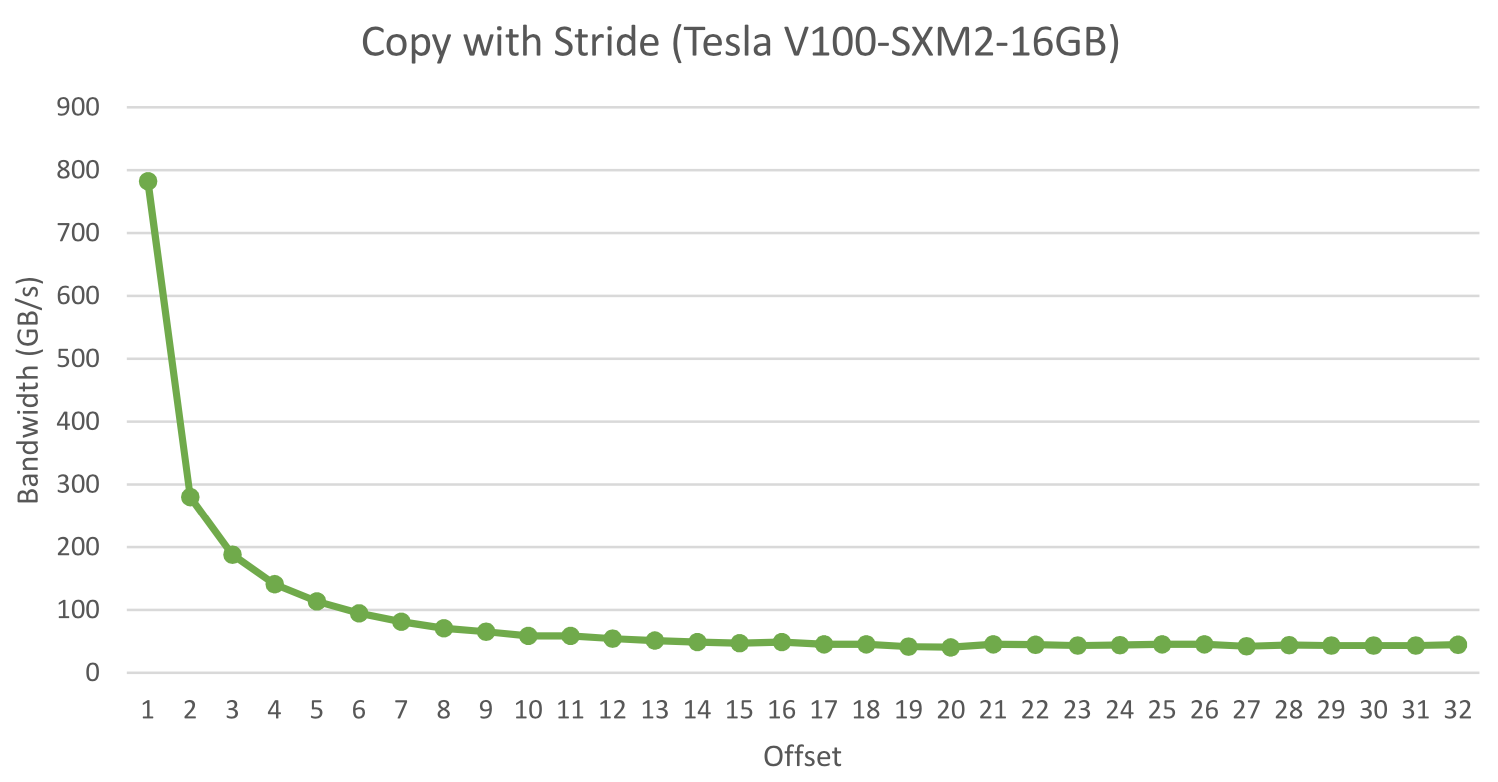
因此,应该尽量避免这样的访存模式。或者使用shared memory。
Shared Memory
Shared Memory比Global Memory有着更高的带宽,更低的延迟和更小的容量。Shared Memory被划分为32-bit大小的bank,即每个bank只能存一个float数,每个bank每个cycle的带宽就是32bit。同一个warp中的32个线程如果访问不同的数据,则可以在同一个clock cycle被并行处理。如果存在多个线程访问同一个bank,则会被硬件线性化访问,从而使得有效带宽降低。
Shared Memory常用于同一个block中的线程需要重复使用Global Memory中的数据的情况。这时,被重用的数据可以提前取到Shared Memory中,避免多次从Global Memory中取数带来的巨大时间开销。例如分块矩阵的乘法C=AB,C的每个分块的结果由多个线程对矩阵A和B的分块计算得到,而A和B的数据会被重复利用,则可以从Global Memory提前取到Shared Memory中。
Cache Hierarchy
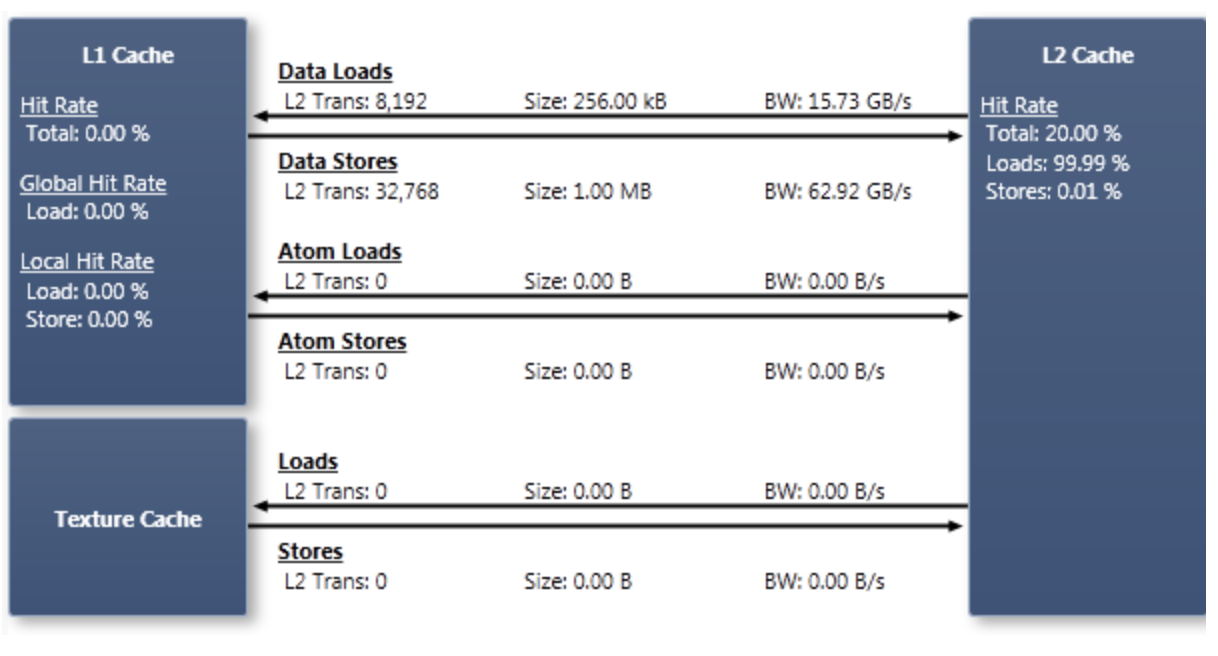
在NVIDIA GPU中,Cache的层级化结构如图所示(来自 NVIDIA ),分为Data Cache(L1、L2)和Texture Cache。L1的一次transaction是128bytes,L2和Texture Cache都是32bytes。因此,一次L1 Cache Miss将会引起4次L2 Cache Access。
何时访问什么Cache:
Global Memory其实是一个逻辑概念,实际上对应于GPU中的Device Memory(DRAM)。一次Global Memory Access并不等于一次DRAM Access,因为要访问的数据可能存在于Cache中,如果在Cache中命中,则不再访问DRAM。Global Memory Access可以分为Global Read Only和Global两类数据通路。Global Access可以使用L1/L2 Cache。而Global Read Only可以额外使用Texture Cache。
Texture Cache采用了与Data Cache非常不同的合并规则(coalescing rules),当需要访问规律性不强的内存地址时,使用Texture Cache可能带来更好的性能。Texture Memory是Device Memory中的一块只读区域。Texture Memory(以及Texture Cache)是专门为访问2维数组而进行了空间局部性优化的一种内存。因此,如果Texture Cache Hit Rate不高,代表程序访存的模式与2维数组的访存模式不太匹配。
GPU的Memory Hierarchy以及Data Path如下图所示(来自StackOverflow):
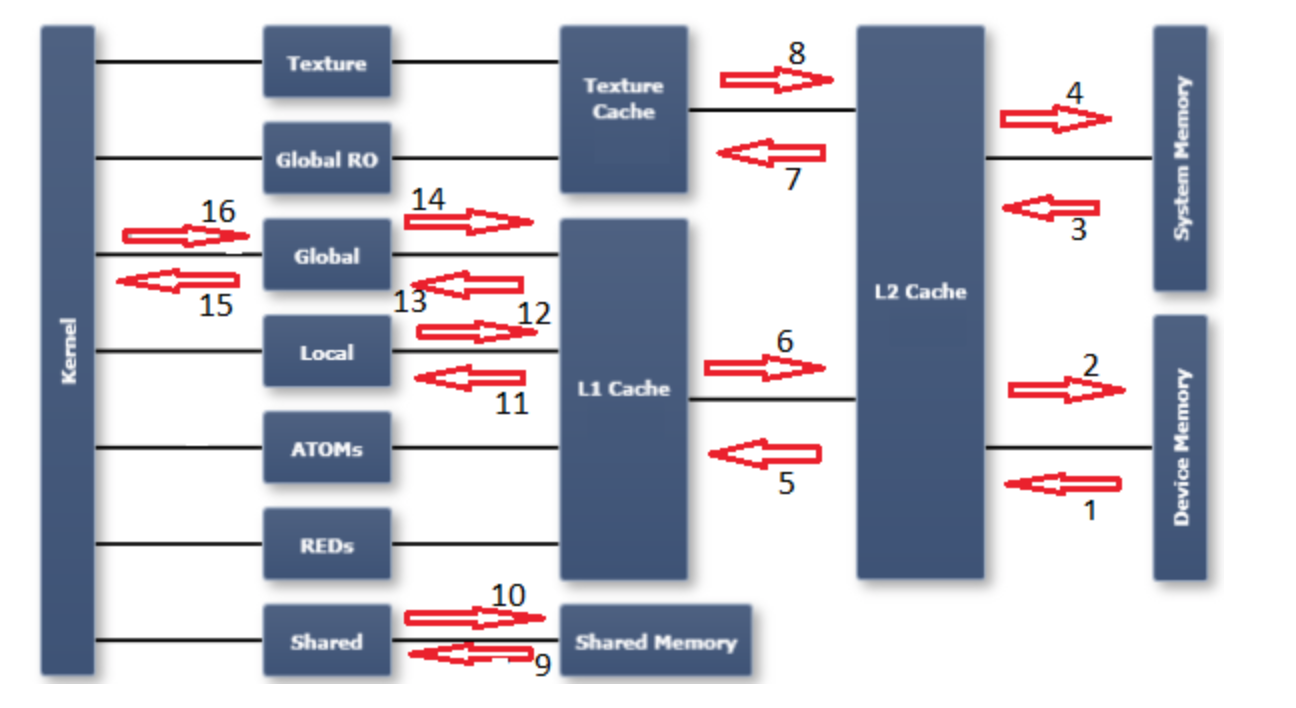
这张图标注出了GPU整个存储架构中可能存在的数据通路。跟nvprof给出的metrics存在如下对应关系:
dram_read_throughputdram_read_transactionsdram_write_throughputdram_write_transactionssystem_read_throughputsystem_read_transactionssystem_write_throughputsystem_write_transactionsl2_l1_read_transactionsl2_l1_read_throughputl2_l1_write_transactionsl2_l1_write_throughputl2_tex_read_transactionsl2_texture_read_throughput- Texture是只读的,这个数据通路不存在
shared_load_throughputshared_load_transactionsshared_store_throughputshared_store_transactionsl1_cache_local_hit_rate- l1 是 write-through cache,这个通路上不存在单独的指标
l1_cache_global_hit_rate- same as 12
gld_efficiencygld_throughputgld_transactionsgst_efficiencygst_throughputgst_transactions
一些思考:
从黑盒视角来看,GPU的性能可以被一些硬件指标和程序本身的指标完全建模,只要两个程序具有相同的浮点运算次数、指令类型、指令效率,硬件存在相同的浮点运算性能和访存带宽,那么这两个程序的运行时间应该是一样的,然而从白盒视角来看,程序内部一个warp中的两个线程,甚至两个warp的线程之间,访问的内存地址不同,就可能造成不同次数的shared memory conflict以及不同的cache miss rate。因此一个准确的性能模型必须对程序本身所执行的操作有一定的了解,才有可能将这些复杂的访存行为纳入其中。因此,我们在构建神经网络中单个op的性能模型时,要避免使用构建通用的GPU kernel性能模型的思路,纯metrics-drien,而要加入我们已有的机器学习背景知识。
另外,在建模时,模型的复杂度也是一个值得深入思考的问题。Roofline模型以及很多Roofline的变体,都是为了用于指导程序性能优化,而非预测程序的运行时间,因此其往往过于简单。而另一些模型,例如文章[4] [5],通过收集大量的硬件指标以及构建抽象的instruction queue来对程序的性能做建模,往往是为了模型更加通用,所以显得过于复杂。当我们只需要构建一个或多个针对神经网络op的性能模型时,其实问题的scope是很小的,并不要求模型有很强的通用性,只需要关注准确性,那么是否可以利用我们对op的一些知识舍弃模型的通用性而提高准确性呢?也是需要思考的问题。
参考文献
[1] CUDA C++ Best Practices Guide
[2] Williams, Samuel, Andrew Waterman, and David Patterson. “Roofline: an insightful visual performance model for multicore architectures.” Communications of the ACM 52.4 (2009): 65-76.
[3] Lopes, André, et al. “Exploring GPU performance, power and energy-efficiency bounds with Cache-aware Roofline Modeling.” 2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 2017.
[4] Konstantinidis, Elias, and Yiannis Cotronis. “A quantitative roofline model for GPU kernel performance estimation using micro-benchmarks and hardware metric profiling.” Journal of Parallel and Distributed Computing 107 (2017): 37-56.
[5] Pei, Ziqian, et al. “Iteration time prediction for CNN in multi-GPU platform: modeling and analysis.” IEEE Access 7 (2019): 64788-64797.