
Performance Model of Convolution on GPU
Published:
背景
GPU Introduction
GPU架构
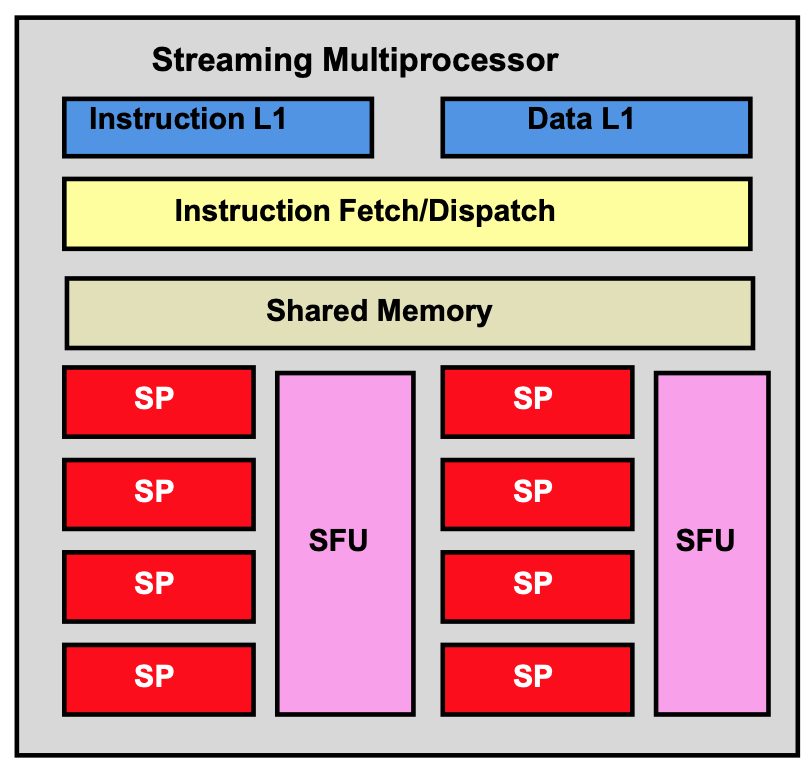
NVIDIA GPU包含多个Stream Multiprocessor(SM)。每个SM的结构如上图所示,其中包含多个Stream Processor(SP)以及数个Special Function Units (SFU),SP是GPU的基本算术指令执行单元,SFU则用于执行一些复杂的操作,例如sin,cos等。除此之外,SM还包含一个几十KB大小的Shared-Memory、一个Instruction Cache和Data Cache,以及一个Multithreading issuing unit用于指令的调度。
GPU 线程
在设计并行程序时,一个很重要的步骤就是对任务进行分解,将任务分解为多个子任务后,使子任务并行执行从而实现加速。
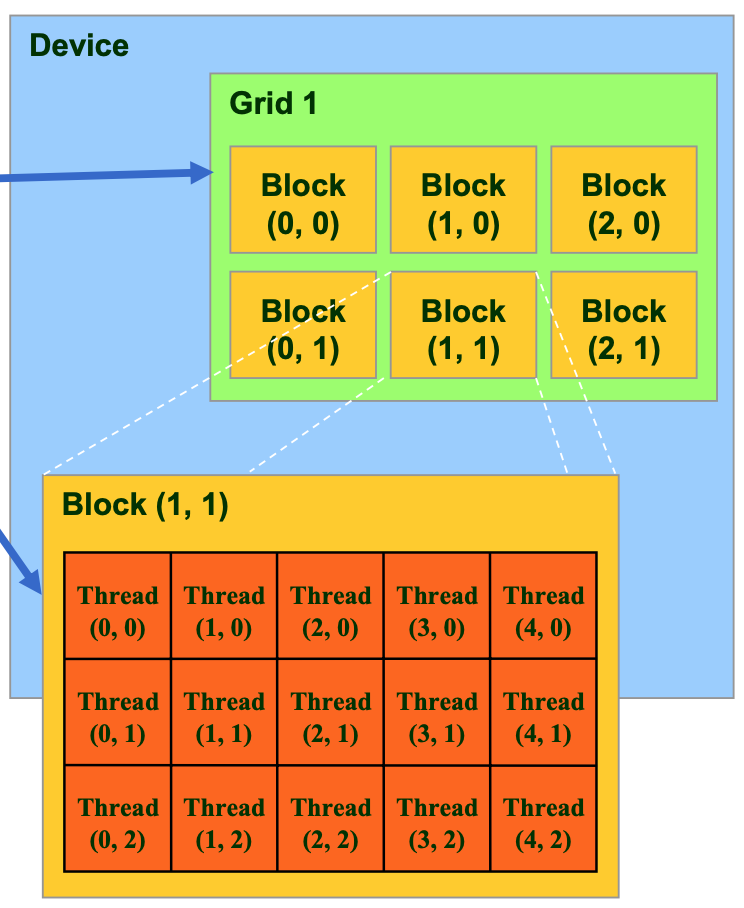
为了简化并行程序的编程难度,在NVIDIA GPU中,线程被组织为线程块(Thread Block),线程块又进一步被组织为线程网格(Thread Grid),如下图所示。在这样的层级化组织架构中,Grid中的每个Block都有一个Block ID,Block中的每个Thread都有一个Thread ID,通过Block ID和Thread ID组合,每一个线程就能获取到自己在整个Grid中的相对位置,也就更容易对自己需要负责的子任务进行计算,对相应的数据进行读写。
我们使用GPU进行计算,是通过编写核函数来实现的,每个核函数可以占用一个线程网格,核函数本身就是对这个线程网格中一个线程需要执行的操作的定义。在编写核函数时,通过Block ID和Thread ID就能实现对任务的分解。在launch核函数时通过指定Grid size和block size就能限定线程网格的大小和线程块的大小。一个线程网格内的所有线程执行的都是一样的核函数,这属于SPMD。
在实际执行时,线程并不是单个被调度,而是按照warp的粒度被调度。一个warp是一个block中Thread ID连续的32个线程,这是GPU中一条指令被执行的最小粒度。也就是说,一个warp是一条SIMD指令,其中的32个线程永远执行一样的指令。
GPU执行一个核函数的大致流程如下:通过CUDA API launch一组线程后,GPU硬件通过一定的调度机制将线程按照block的粒度调度给SM(每个block可能被调度到任何一个SM上),SM中的调度器将block划分为warp,并按照warp的粒度将线程调度到SP上执行。当一个warp下一条指令所需的数据已经准备好了(从global memory 拷贝到了shared memory),那么这个warp就会被调度执行。
Warp size是一个可能会变化的数量,但目前所有NVIDIA GPU的warp size都是32。
GPU 存储架构
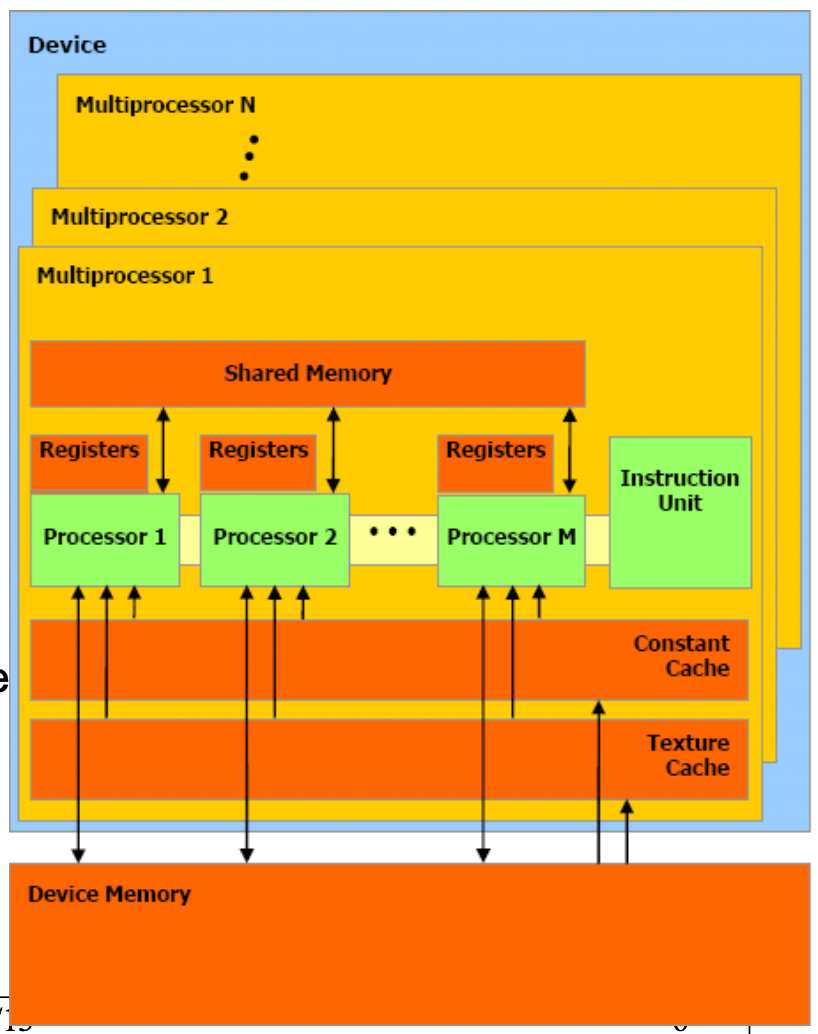
GPU的存储架构如上图所示,包含以下几种内存单元:
- Register。在每个SM中包含一定数量的register。register只能被单个线程所使用,一旦一个register被分配给某个线程,其他线程便无法访问这个register。register的访问延迟很低,只有1个cycle。
- Shared Memory。Shared memory也是每个SM内部所包含的,但shared memory可供一个block内部所有的线程共享,因此可以使用shared memory存储需要在多个线程之间读取或修改的数据。shared memory一般被分为固定大小的bank。其访问延迟也只有1个cycle,但bank conflic可能会降低访问的性能。
- Global Memory。Global memory是GPU的device memory,可供一个grid中的所有block共享,并且也是跟CPU memory进行交换的”窗口“,通过cudaMemcpy()从Host device拷贝数据到GPU,就是存放在global memory。但global memory的访问延迟非常高,需要约500个cycle。
- Local Memory。Local memory是可供单个线程使用的一种存储空间,其本质上是global memory的一部分,当线程耗尽SM中的register时,就会使用local memory。其访问延迟跟global memory一样。
- Texture Memory。Texture memory是可供一个grid中所有block共享的一类global memory,为图像处理进行了优化,需要通过特殊的API使用,并不常用。
跳变现象(Quantization)
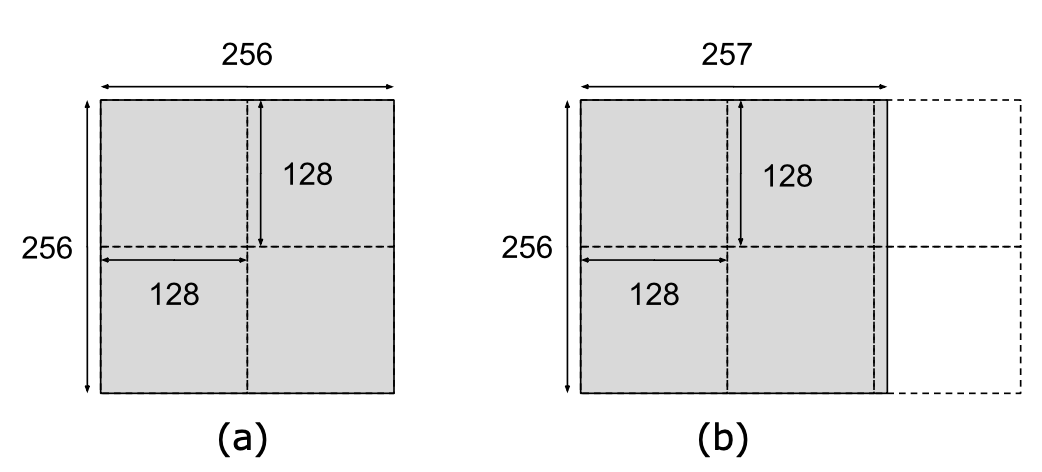
介绍完GPU的架构和线程执行流程后,我们就能比较容易理解GPU中的”跳变“现象(Quantization)。这里有一个矩阵乘的例子,假设如图的矩阵(a)要和另一个矩阵做乘法,我们通过分块矩阵乘实现并行计算。如果我们设置的分块大小为128x128,那么这个矩阵刚好能被分为4块,每一个线程执行的都是有用的计算,没有任何性能被浪费,非常完美。但是如果矩阵(b)是一个256x257的矩阵,不能刚好被划分为4块,需要被划分为6块,那么多出来的两块也会执行和其他分块一样多的计算量,耗费一样多的时间。但其中绝大部分是无用的计算,虽然程序的正确性能够被保证,但性能被极大地降低了。如果对矩阵乘($K\times N$与$N\times M$相乘)这个例子在维度N上进行连续的测试,就能得到以下结果:图中横坐标代表$N$的大小,纵坐标代表乘法时间,从图中可以看到非常明显的”跳变“现象,$N$从256增加到257时,时间大约增加了50%。
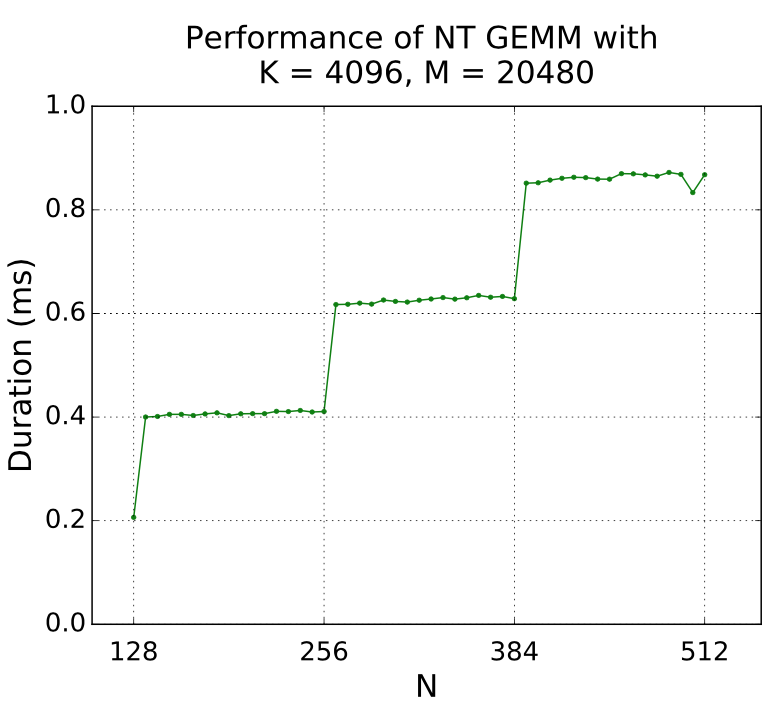
不只是矩阵乘会出现这样的跳变现象,任何对计算任务做划分,并行执行子任务的CUDA程序都有可能出现这样的跳变现象,不同算法对任务的划分方式不一样,出现跳变的维度就会不同,要对CUDA算法的性能进行建模,跳变现象是不可忽视的一个重要影响因素,需要根据具体的算法进行具体的分析,才能得到比较准确的模型。
以上跳变现象在NVIDIA的官方文档中被称为”Tile Quantization“,还有一类跳变被称为”Wave Quantization“,Wave Quantization跟block的数量有关,如果一个计算任务的所有block(假设为$n$个)刚好能被所有的SM(假设为$n$个)并行计算,就能得到最佳的性能,此时如果再增加一个block,为了计算这一个block,GPU所需要的时间其实跟计算$n$个block的时间是一样的,因此就会形成跳变现象。
cuDNN
cuDNN是NVIDIA提供的用于加速GPU上神经网络计算过程的库,其中,卷积被实现为3大类算法:GEMM类、FFT类以及Winograd类。GEMM有三种变体:GEMM、GEMM_IMPLICIT、GEMM_IMPLICIT_PRECOMP;FFT有两种变体:FFT、FFT_TILING;Winograd有两种变体:WINOGRAD、WINOGRAD_NON_FUSED。在下面的章节中,我们将详细介绍这几类算法的实现原理及模型。
Performance Model
GEMM及其变体
实现原理
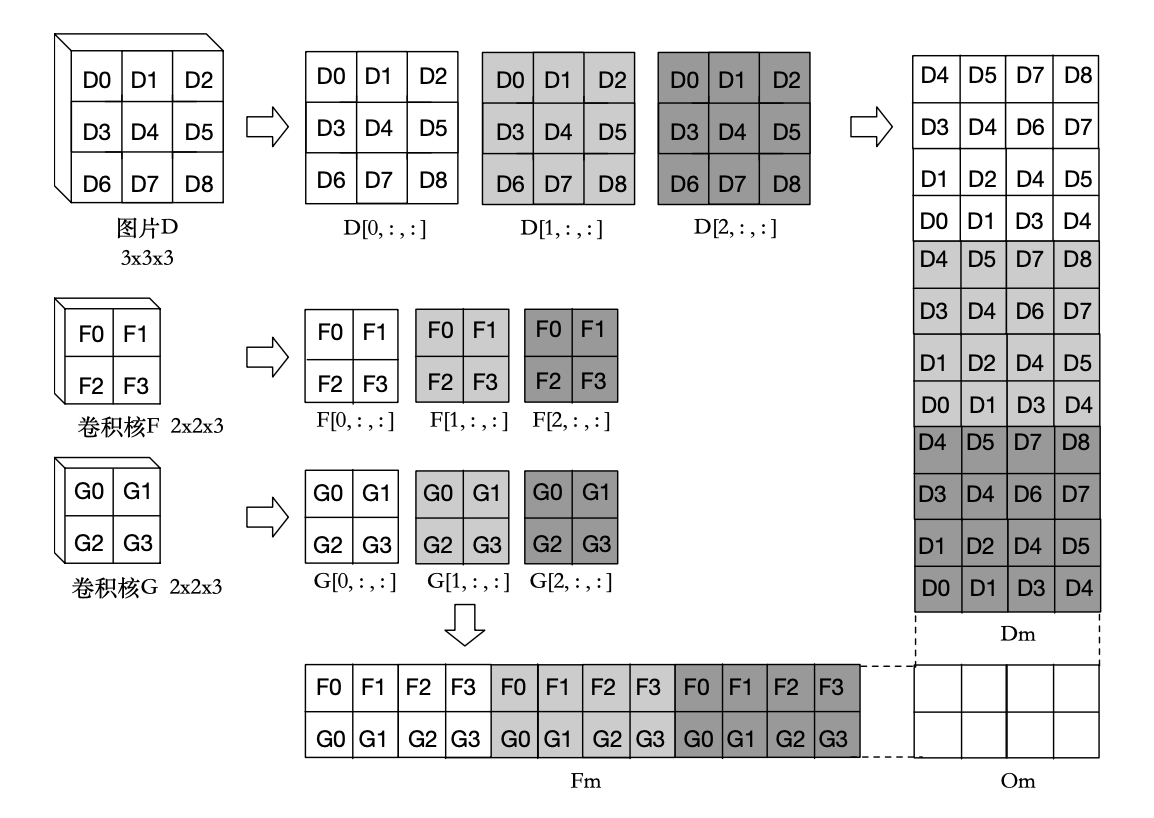
最常见的卷积算法的实现是基于BLAS GEMM矩阵乘法的。在进行卷积之前首先将要进行卷积的图片和卷积核转化为矩阵。如图所示,是一个 3x3x3 的图片 $D$ 与两个 2x2x3 的卷积核 $F,G$ 进行卷积操作的过程。先将原始图片 $D$ 由一个三维张量转化为一个二维矩阵 $D_m$,矩阵的每一列是卷积核每一步在图片上的作用域所包含的数值所形成的一维列向量。 矩阵的列数就是卷积核总共对该图片的作用次数。再将所有的卷积核转化为一个二维矩阵 $F_m$,矩阵的每一行是一个卷积核展开形成的一维行向量,矩阵的行数就是卷积核的个数。最终两个矩阵相乘得到的结果矩阵 $O_m$ 的每一行是卷积操作输出图片的一个通道的一维展开向量,行数就是结果的输出通道数。
在cuDNN中,GEMM不仅有直接实现的版本,也有其他两种变体。直接实现的GEMM,由于要存储转换后的中间矩阵,需要占用大量的内存。另外两种变体是IMPLICIT_GEMM和IMPLICT_PRECOMP_GEMM,这两种实现都不需要存储中间矩阵,因为他们的中间矩阵是在GEMM核函数中即时计算的,并且IMPLICT_PRECOMP_GEMM还会提前调用另一个核函数提前计算一些indice,用于即时的矩阵转换过程。
WINOGRAD
实现原理
这一类卷积算法基于Winograd’s minimal filtering algorithms来实现。其本质上是通过增多加法次数来减少乘法次数,因为加法比乘法耗时更短,因此这类算法能在某些参数组合下带来很大的性能提升。由于Winograd算法中的加法次数随着输入图片的大小呈平方增大,因此Winograd算法只适用于较小的输入。
在cuDNN中,Winograd算法也有两种实现,一种是fused Winograd,一种是non-fused Winograd,区别就在于对于输入、卷积核的转换过程一并放到Winograd核函数中还是单独用一个核函数来计算。
现阶段的cuDNN对于Winograd算法的使用有一定的限制条件:对于Winograd(fused)只支持3x3卷积和步长为1的情况,对于Winograd no-fused,只支持3x3卷积和5x5卷积,步长为1的情况。
FFT
实现原理
两个输入的卷积的傅里叶变换等于这两个输入的傅里叶变换的乘积,即时域中的卷积等于频域中的按位乘法。因此,我们要进行卷积操作时,可以先对输入图片和卷积核进行傅里叶变换,再对变换后的结果进行乘法操作,将计算得到的结果进行逆傅里叶变换,从而得到输出图片。这就是用傅里叶变换实现卷积的原理。之所以傅里叶变换能在某些参数组合下带来性能的提升,是因为乘法操作比卷积操作的计算量更小,因此,如果对输入和输出进行傅里叶变换的时间相比总时间较少,那么总体性能就能得到提升。然而,对单个图片或卷积核进行傅里叶变换的开销是比较大的,因此FFT类算法更适用于输入图片数量(batch size)较大或卷积核比较多(out_chan)、比较大(kernel_wid)的情况,因为对输入进行傅里叶变换的结果会被多次使用,分摊了傅里叶变换的开销。
不过目前深度学习领域的主流趋势是使用较小的卷积核,因为研究者发现,使用多个较小的卷积核就能模拟一个大卷积核的效果,且执行的计算次数大幅减少,能提高神经网络的性能。因此,FFT及其变体在实际的神经网络上很少会被用到。
现阶段的cuDNN对于FFT类算法的使用有一定的限制条件:对于FFT,其输入图片加上padding之后的宽度和高度不能超过256,只支持步长为1的情况,并且要求卷积核高度大于padding高度,卷积核宽度大于padding宽度;FFT_TILING是FFT的一个变体,其实现上就是把输入图片分块为更小的图片,因此这个算法对输入图片的大小没有要求,其余要求与FFT相同。
TO BE UPDATED: 我们针对各类算法提出了相应的性能模型,目前正在进一步优化。模型完善后将会更新本文档。